Introduction to scikit-multichannel¶
Scikit-multichannel is a Python library for automating aspects of the machine learning (ML) workflow and for building noise-resistant ML pipelines that learn fast from a limited number of samples. It features:
a multichannel pipeline architecture
support for scikit-learn compatible components
ensemble learning
channel ensembles
model ensembles
voting, aggregating, stacked generalization
internal cross validation training
tools for managing complex pipeline architectures:
Keras-like layers
visual feedback during pipeline construction
in-pipeline workflow automation (or ‘semi-auto-ML’):
screening of input sources based on aggregate features score or performance of a probe ML model
screening of ML algorithms
screening of model hyperparameters
fast distributed computing with ray
>90% unit test coverage for the alpha releases
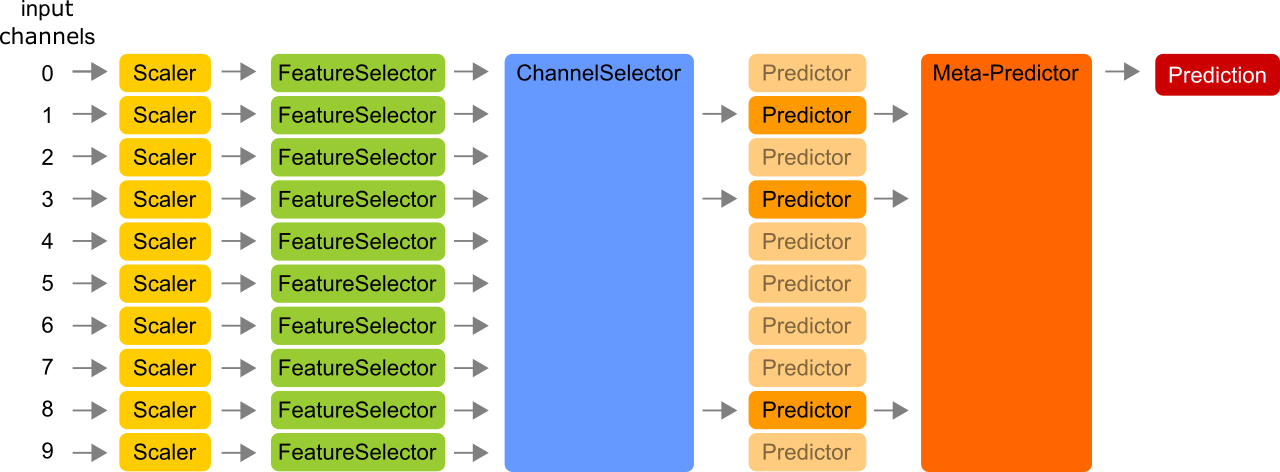
# build the pipeline architecture depicted above
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.svm import SVC
import skmultichanneal as sm
Xs, y, X_type = sm.make_multi_input_classification(n_informative_Xs=3,
n_random_Xs=7)
clf = sm.MultichannelPipeline(n_channels=10)
clf.add_layer(StandardScaler())
clf.add_layer(SelectKBest(f_classif, k=10))
clf.add_layer(sm.SelectKBestScores(f_classif, np.sum, k=3))
clf.add_layer(sm.make_cv_transformer(GradientBoostingClassifier()))
clf.add_layer(sm.MultichannelPredictor(SVC()))
sm.cross_val_score(clf, Xs, y)
# output (balanced accuracy): [0.97, 0.85, 1.0]
What is a multichannel pipeline?¶
A multichannel pipeline is an ML pipeline that takes multiple input matrices and processes them in separate channels before combining them through concatenation, voting, or model stacking to generate a single prediction.
See:
MultichannelPipeline
Why use a multichannel architecture?¶
When you have multiple input matrices coming from different data sources or feature extraction methods, you can sometimes get better model performance by training a separate ML model on each input and then making an ensemble prediction. This performance boost may be due to increased diversity of utilized features.
You have a large number of input sources and want to define quality criteria for input into your model, either because input selection improves model performance or it reduces the computational cost of model training. Scikit-multichannel provides pipeline components for selecting inputs based on feature scores or performance metrics of a probe ML model.
You want to include a feature selection stage and ensure that features from each of your input sources are represented in the final selection. Scikit-multichannel makes it easy to guarantee feature diversity by applying feature selection on a per-input basis.
Distributed computing with ray¶
Scikit-multichannel uses the ray library to speed up multiprocessing by passing arguments through a distributed in-memory object store without the usual serialization/deserialization overhead and without passing the same object multiple times when needed by multiple jobs. Ray also enables skmultichannel to rapidly distribute jobs among networked computers.
Installation¶
pip install scikit-multichannel
or:
git clone https://github.com/ajcallegari/scikit-multichannel.git
cd scikit-multichannel
pip install .
Scikit-multichannel was developed with Python 3.7.5 and tested with the following dependencies:
numpy==1.17.2
joblib==0.16.0
ray==1.1.0
scipy==1.3.1
pandas==0.24.2
scikit-learn==0.23.2
Thanks to Ilya Goldberg and Josiah Johnston for the fascinating conversations that inspired Scikit-multichannel.
Scikit-multichannel was developed by A. John Callegari